
At Google, we're constantly trying to find new ways to organize the world's information, including information relevant to our business. Building on the ideas of Friedrich Hayek and the Iowa Electronic Markets, a few Googlers (Doug Banks, Patri Friedman, Ilya Kirnos, Piaw Na and me, with some help from Hal Varian), set up a predictive market system inside the company.
 The markets were designed to forecast product launch dates, new office openings, and many other things of strategic importance to Google. So far, more than a thousand Googlers have bid on 146 events in 43 different subject areas (no payment is required to play).
The markets were designed to forecast product launch dates, new office openings, and many other things of strategic importance to Google. So far, more than a thousand Googlers have bid on 146 events in 43 different subject areas (no payment is required to play).We designed the market so that the price of an event should, in theory, reflect a consensus probability that the event will occur. To determine accuracy of the market, we looked at the connection between prices of events and the frequency with which they actually occurred. If prices are correct, events priced at 10 cents should occur about 10 percent of the time.
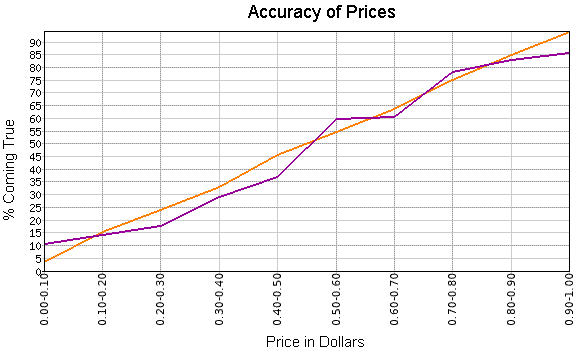
In the graph below, the X-axis indicates the price ranges for the group. The orange line represents the average price, which is how often outcomes in that group should actually happen according to market prices. The purple line is how often they did happen. Ideally these would be equal, and as you can see they're pretty close. So our prices really do represent probabilities - very exciting!
 We also found that the market prices gave decisive, informative predictions in the sense that their predictive power increased as time passed and uncertainty was resolved. When a market first opens there may be considerable uncertainty about what will eventually happen; but as time goes on, some outcomes became more likely than others. The market prices should reflect this phenomenon, with the implied probability distributions becoming more concentrated over time.
We also found that the market prices gave decisive, informative predictions in the sense that their predictive power increased as time passed and uncertainty was resolved. When a market first opens there may be considerable uncertainty about what will eventually happen; but as time goes on, some outcomes became more likely than others. The market prices should reflect this phenomenon, with the implied probability distributions becoming more concentrated over time.Being geeks, we naturally used information theory to measure the entropy of our probability distributions:
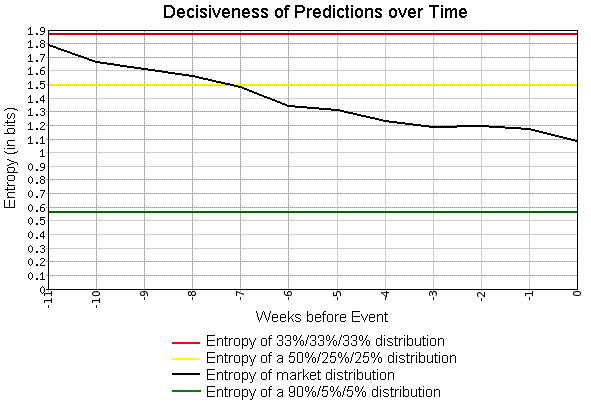 In this graph, we have weeks before market expiration on the X-axis, and entropy (in bits) on the Y-axis. We've included some reference entropies to help your intuition, and you can see that in addition to accurate predictions, the distributions become steadily more informative and decisive (lower entropy) over time.
In this graph, we have weeks before market expiration on the X-axis, and entropy (in bits) on the Y-axis. We've included some reference entropies to help your intuition, and you can see that in addition to accurate predictions, the distributions become steadily more informative and decisive (lower entropy) over time.Our search engine works well because it aggregates information dispersed across the web, and our internal predictive markets are based on the same principle: Googlers from across the company contribute knowledge and opinions which are aggregated into a forecast by the market. Sometimes, just feeling lucky isn't enough, and these tools can help.





